Machine learning for robot manipulation promises to unlock generalization to novel tasks and environments.
But how should we measure the progress of these policies towards generalization?
Evaluating and quantifying generalization is the Wild West of modern robotics, with each work proposing and measuring different types of generalization in their own, often difficult to reproduce settings.
In this work, our goal is (1) to outline the forms of generalization we believe are important for robot manipulation in a comprehensive and fine-grained manner, and (2) to provide reproducible guidelines for measuring these notions of generalization.
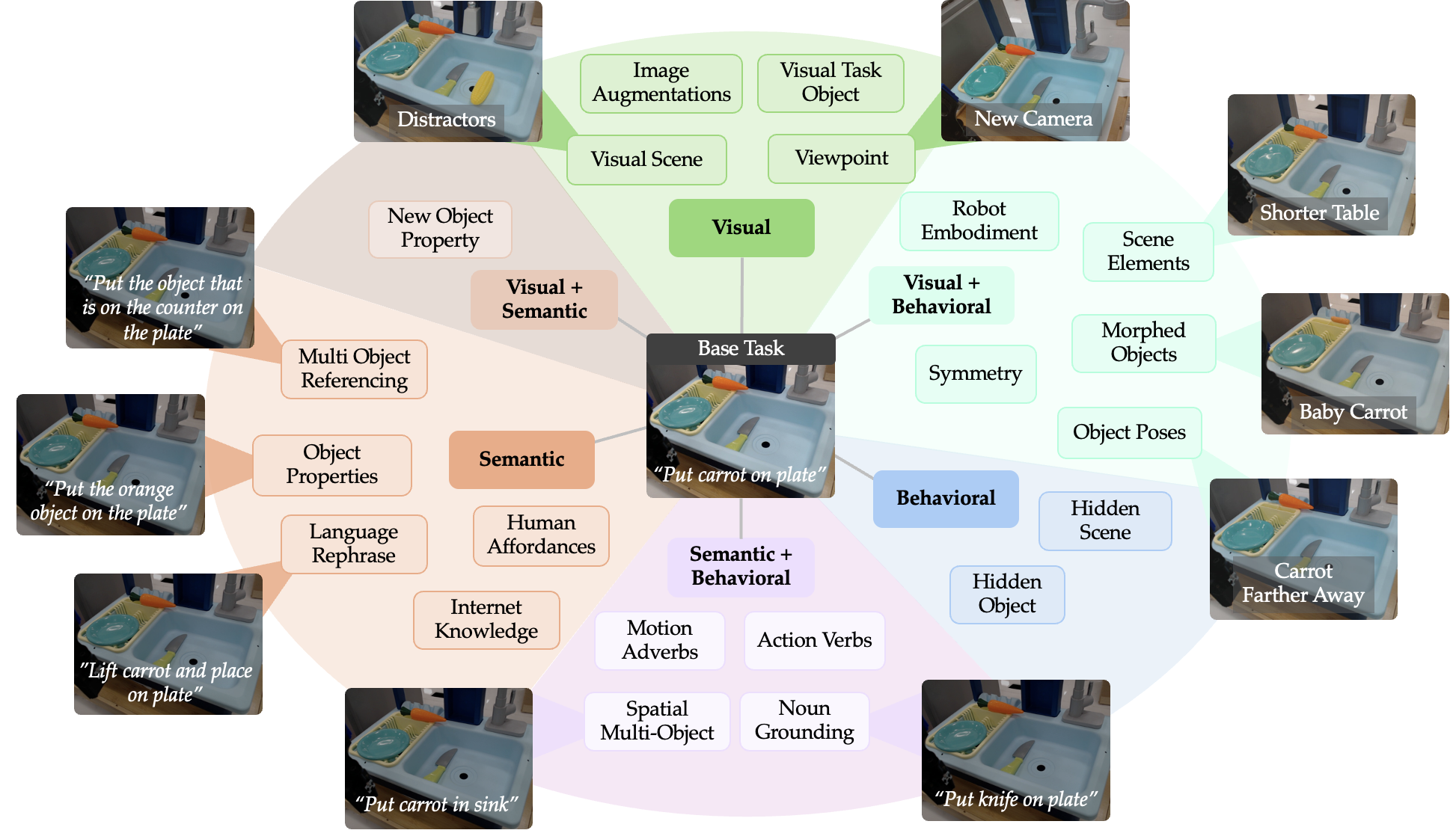
We first propose ★-Gen, a taxonomy of generalization for robot manipulation structured around visual, semantic, and behavioral generalization.
Next, we instantiate ★-Gen with two case studies on real-world benchmarking: one based on open-source models and the Bridge V2 dataset, and another based on the bimanual ALOHA 2 platform that covers more dexterous and longer horizon tasks.
Our case studies reveal many interesting insights: for example, we observe that open-source vision-language-action models often struggle with semantic generalization, despite pre-training on internet-scale language datasets.
Our Taxonomy: ★-Gen
Generalization in robotics can be a nebulous, ill-defined concept. We formalize generalization intuitively as perturbations relative to some base task.
For visual-lingual control policies, such as vision-language-action models (VLAs), these perturbations can fall under three main types:
Visual: Changes to the initial scene image.
Semantic: Changes to the language instruction.
Behavioral: Changes to the expert action distribution.
A given perturbation might lie at the intersection of one or more of these types. For example, changing the location of a carrot in the task "put carrot on plate" changes both the image (Visual) and the required actions (Behavioral).
Therefore, we can categorize perturbations into categories of generalization depending on which combination of the above perturbation types they affect.
For example, changing the location of the carrot would fall under the Visual + Behavioral category.
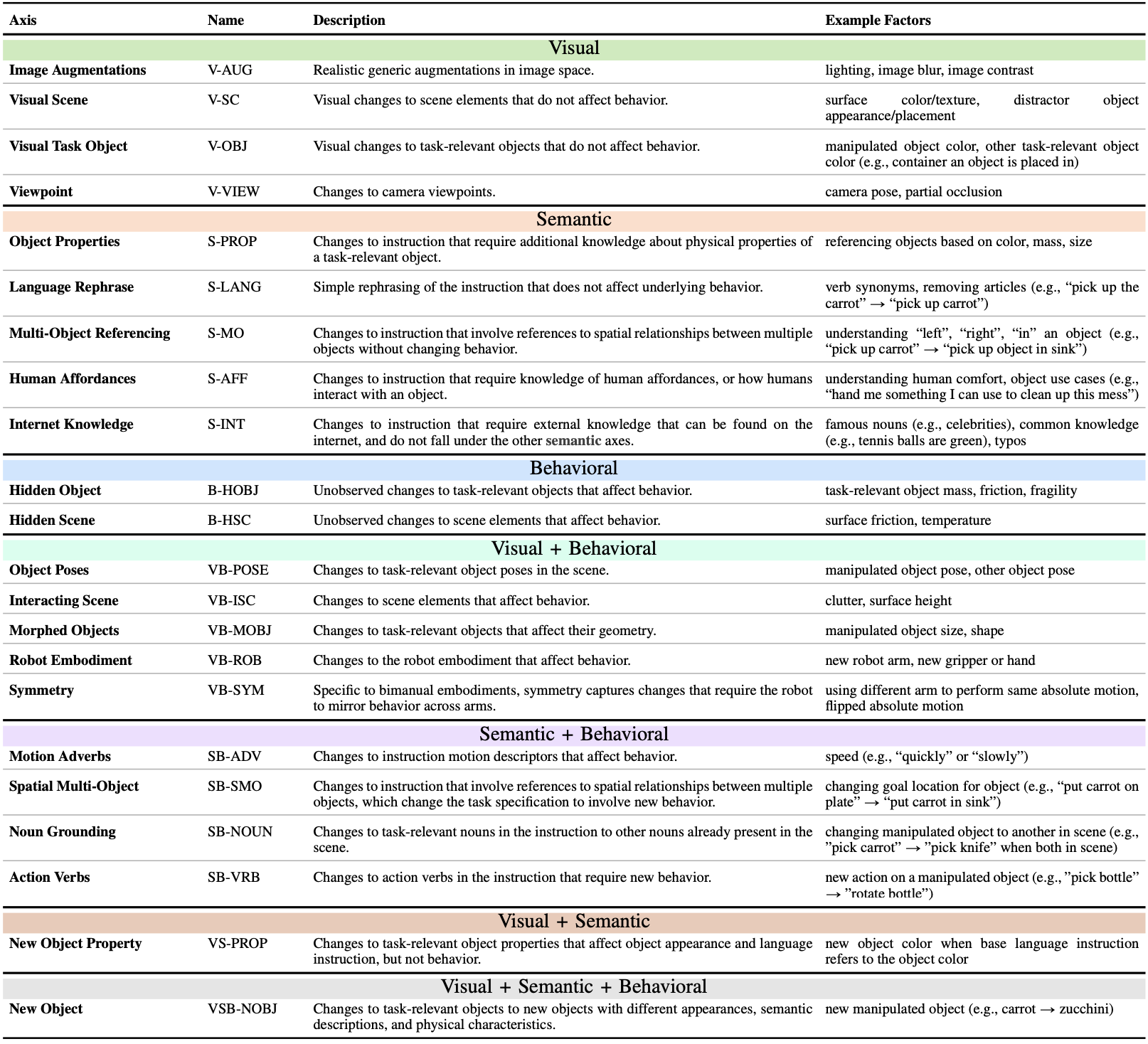
We further group different perturbations in each category into human-interpretable axes of generalization. Below you can find the axes we have enumerated for each category of generalization.
Detailed Axes of Generalization.
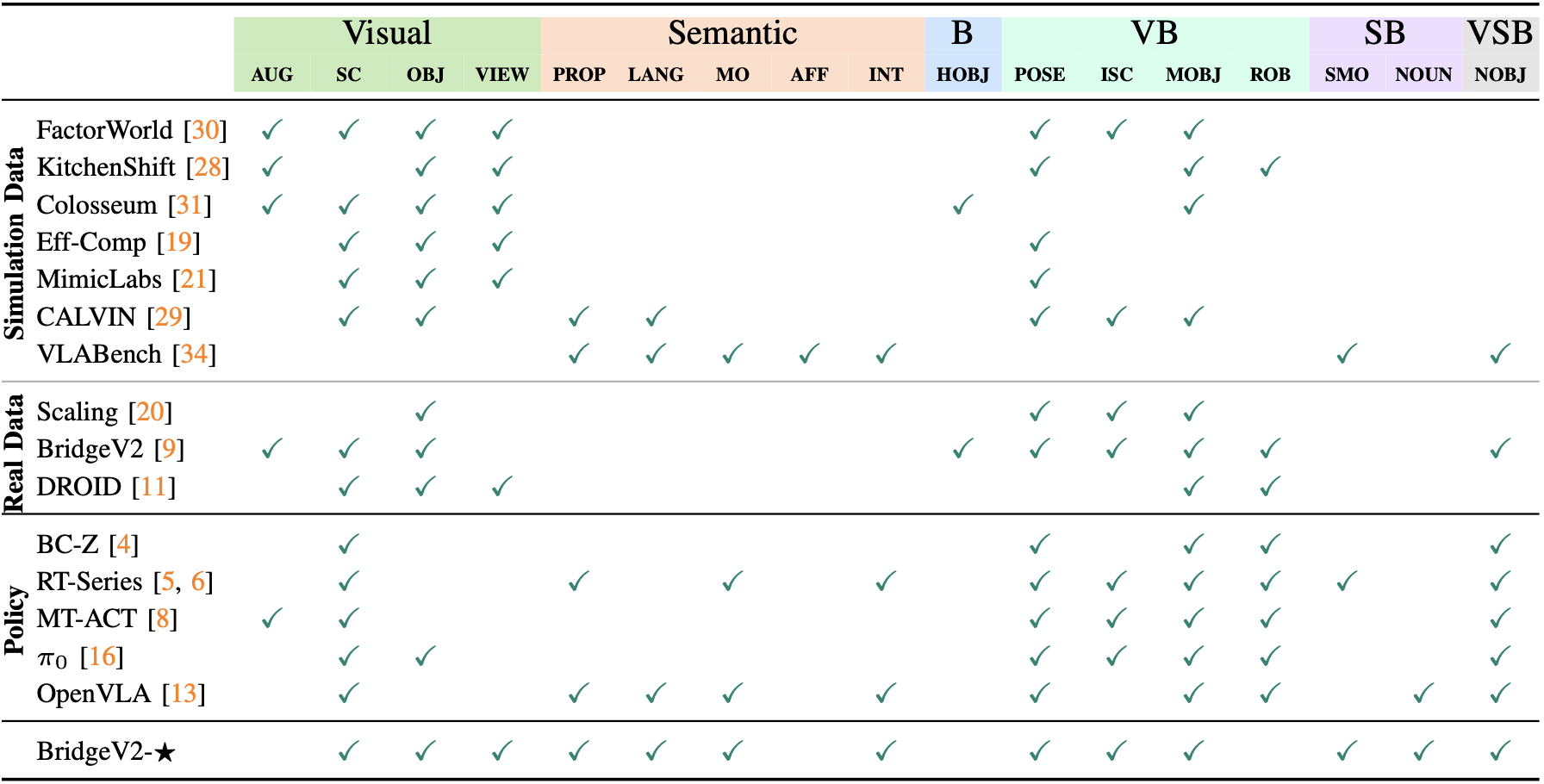
These axes span a wide range of possible perturbations, and we show below that ★-Gen encompasses notions of generalization in prior work:
Comparing ★-Gen to notions of generalization in prior work, as well as our benchmark BridgeV2-★ .
Instantiating our Taxonomy: BridgeV2-★
We walk through an example of instantiating our taxonomy ★-Gen into a real-world benchmark for generalization evaluation.
We use the popular Bridge-V2 dataset as a starting point, and we train several state of the art models:
OpenVLA, MiniVLA, and \( \pi_0 \). We pick the following base tasks which are aligned with the Bridge-V2 dataset,
and collect 20-50 additional demos per task to ensure they are in distribution for our setup.
Put carrot on plate
Put knife on plate
Flip pot upright
Put plate in sink
For each of these base tasks, we chose perturbations along a subset of our axes, since some axes did not have meaningful instatiations on this dataset.
Please refer to our paper for details on the specific evaluation tasks we used.
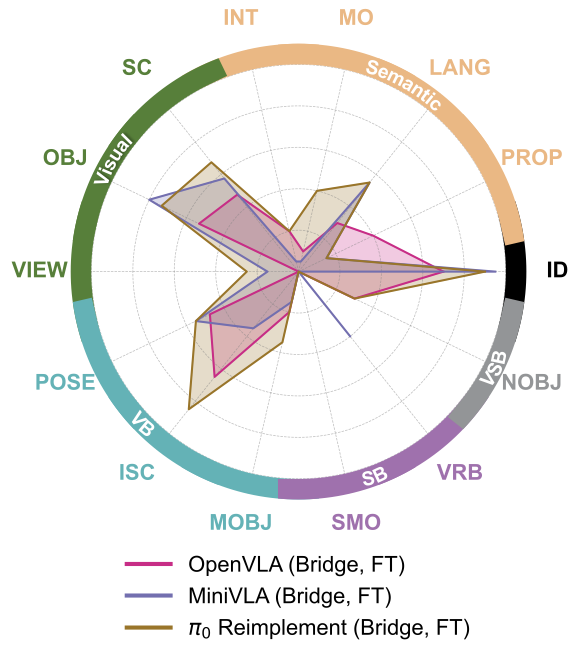
BridgeV2-★ Main results.
Our main results on our BridgeV2-★ benchmark are shown on the left, which consists of in-distribution base task
performance, and 55 task variations that span 13 of our axes,
for a total of 885 real-world evaluations. We find that existing
generalist policies tend to struggle on most of our considered
axes. In particular, semantic generalization is mostly weak,
despite the use of language model backbones. This has interesting
implications: e.g., rather than relying only on language model
initialization to improve semantic generalization,
perhaps other mechanisms are needed, such as improving
robot language annotations.
Each model tends to have similar strengths and weaknesses.
However, there are some notable
differences between each model that the fine-grained nature
of our benchmark helps reveal. For example, OpenVLA is
noticeably worse at visual generalization,
while MiniVLA struggles more with visual
+ behavioral. OpenVLA is the best
at understanding object properties, but still
struggles with other semantic axes \( \pi_0 \)
generally performs the best, possibly due to
a more capable VLM backbone (PaliGemma), and/or better
architecture (flow-based action chunking). However,
all models generally struggle in terms
of absolute performance for most axes.
We also consider varying different model design decisions to better understand their impact on generalization,
with t-tests to assess statistical significance.
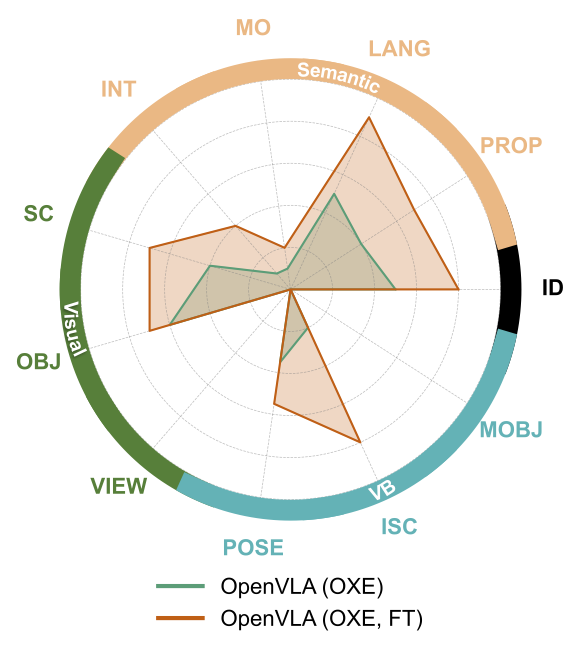
(a) Scaling Robot Data:
We compare our Bridge-only OpenVLA with a version trained on a significantly larger,
cross-embodiment OXE mixture. Consistent with prior work,
we find that larger and more diverse datasets can significantly improve forms of generalization,
such as for visual + behavioral axes (M = 0.22 vs. M = 0.48), t(7) = -2.76, p = 0.028.
However, the axes on which the Bridge-only model struggled the most
(Viewpoint, Morphed Objects, Multi-Object Referencing) do not improve significantly.
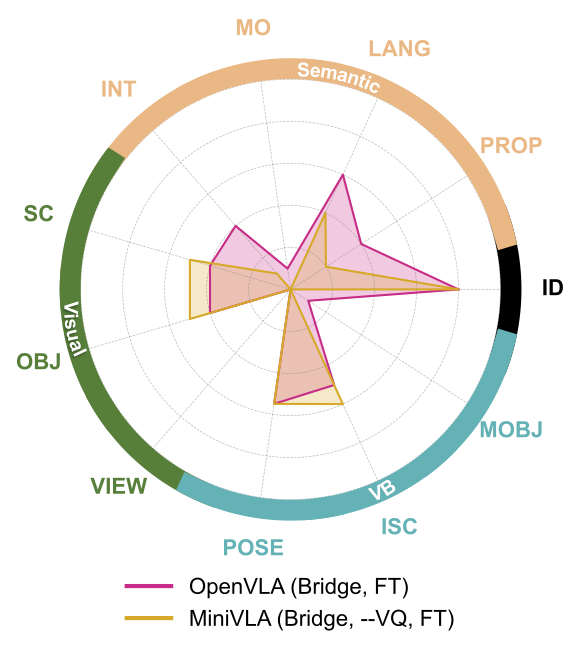
(b) Scaling LLM Backbone:
We compare VLA policies that differ only in the large language model (LLM) backbone.
Specifically, we compare OpenVLA (Bridge, FT), using Llama 2 7B, and MiniVLA (Bridge, --VQ, FT), using Qwen2.5 0.5B.
We find that while the larger LLM improves semantic axes,
it is not by a significant amount (M = 0.18 vs. M = 0.35), t(7) = -1.87, p = 0.104.
Absolute performance for these and other axes also remain low,
suggesting that scaling LLMs only has limited benefits.
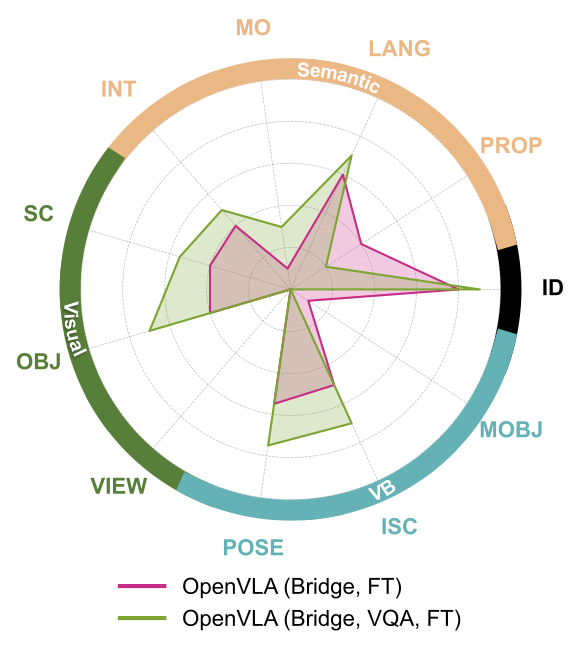
(c) VQA Co-training:
We investigate co-training with visual-question answering (VQA) data,
which prior work has shown to improve generalization.
We find this can help, such as for visual axes (M = 0.30 vs. M = 0.45), t(7) = -2.39, p = 0.048.
However, there is surprisingly a mixed effect for semantic axes (M = 0.38 vs. M= 0.42), t(7) = -0.51, p = 0.626,
improving three of them, but hurting Object Properties.
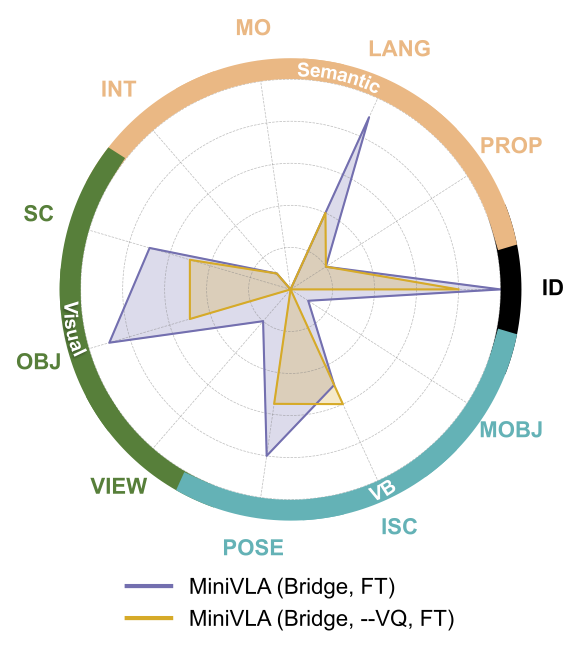
(d) Vector Quantized Actions:
We investigate using binning-based tokenization instead of vector quantized action chunking with MiniVLA.
We find that VQ action chunking helps nearly all axes,
including visual axes by a significant amount (M = 0.38 vs. M = 0.62), t(7) = -2.38, p = 0.049.
This highlights the importance of action chunking and tokenization methods,
as also suggested by prior work.
Example Generalization Axes & Evals
Below we visualize rollouts from the policy under each of our axes of generalization tested in our benchmark BridgeV2-★.
For each row, the left video shows the base task, and the right slider (and color-coded scroll buttons below the videos) shows an example generalization condition for that axis.
These videos are real rollouts from our evaluation.
BASE TASK: Put carrot on plate
V-SC: distractors
V-OBJ: orange plate
V-VIEW: new camera view
S-PROP: Put the orange object on the plate
S-LANG: Lift carrot and place on plate
S-MO: Put the object that is on the counter on the plate
S-INT: Put the object that is the same color as a basketball on the plate
Here we provide a demo of using Gemini 2.0 Flash to automatically generate evaluation conditions for a base task according to ★-Gen.
First, provide a Gemini API key, which can be generated here (this will only be stored locally).
Then, provide a base task by uploading a scene image (under 1 MB) and providing a language instruction.
You may then choose an axis from ★-Gen from one of the options in the drop-down menu, and Gemini will suggest new perturbed tasks for evaluating the chosen axis.
Disclaimer: The generated perturbations are not guaranteed to accurately reflect the chosen axis.